設定
例によって設定から。今回はみんな大好きirisで試します。
1 | from sklearn.datasets import load_iris |
データのインポート
まずは読み込んで、、、1
2## irisのデータセットのload
iris = load_iris()
どんなデータだったかみたい場合は、iris.DESCRで確認しましょう。print()を使った方が読みやすいと思います。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19print(iris.DESCR)
#.. _iris_dataset:
#
#Iris plants dataset
#--------------------
#
#**Data Set Characteristics:**
#
# :Number of Instances: 150 (50 in each of three classes)
# :Number of Attributes: 4 numeric, predictive attributes and the class
# :Attribute Information:
# - sepal length in cm
# - sepal width in cm
# - petal length in cm
# - petal width in cm
# - class:
# - Iris-Setosa
# - Iris-Versicolour
# - Iris-Virginica
Setosa, Versicolour, Virginicaの3種別あるで、多クラス分類ですね。
データをpytorchが読めるようにする
中身を見てみましょうか。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18## 説明変数用(numpy形式で格納)
iris.data[:5] ## はじめの5行分だけ眺めてみます
#array([[5.1, 3.5, 1.4, 0.2],
# [4.9, 3. , 1.4, 0.2],
# [4.7, 3.2, 1.3, 0.2],
# [4.6, 3.1, 1.5, 0.2],
# [5. , 3.6, 1.4, 0.2]])
## こっちは目的変数用(こっちもnumpy形式ですね)
iris.target
#array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
# 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
# 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
# 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
# 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
値が0, 1, 2という値ですね。
多クラス分類を考える時、このようなラベル名をそのまま当てはめる場合とベクトルに直さないとライブラリが使えなくなったりするので、要注意ですね。つまり、
のようにベクトル化することが必要な場合とがあります。
1 | train_X = torch.Tensor(iris.data) ## torch.Tensor型: Pytorch版のnumpy形式 |
通常、学習データ、評価データを分割して過学習(overfit)してないか?とか見るのが通常ですが、
今回は取り敢えずモデルが作れるところを主軸にしたいので敢えて学習しかしてません。
モデルの骨格
1 | ## まずはNeural Networkを使うよってことでnn.Moduleを継承します |
F.log_softmax()は、数学的にはlog(softmax())と同等のようですが、中身のsoftmax()の値がになってしまうとなので計算出来ません。ということで、F.log_softmaxは別の実装によりその状況を避けているようで
モデルの骨格が出来たのでメモリに載せます(インスタンス化)
1 | model = Net() |
学習させます!
1 | ## 誤差の収束方法をSGD(Stochastic Gradient Descent), lr(learning rate)を設定 |
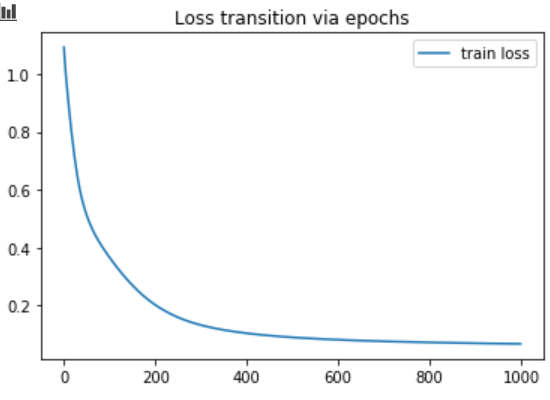
学習過程を図示します
1 | plt.figure() |